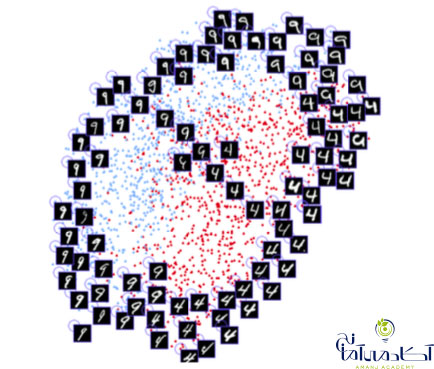
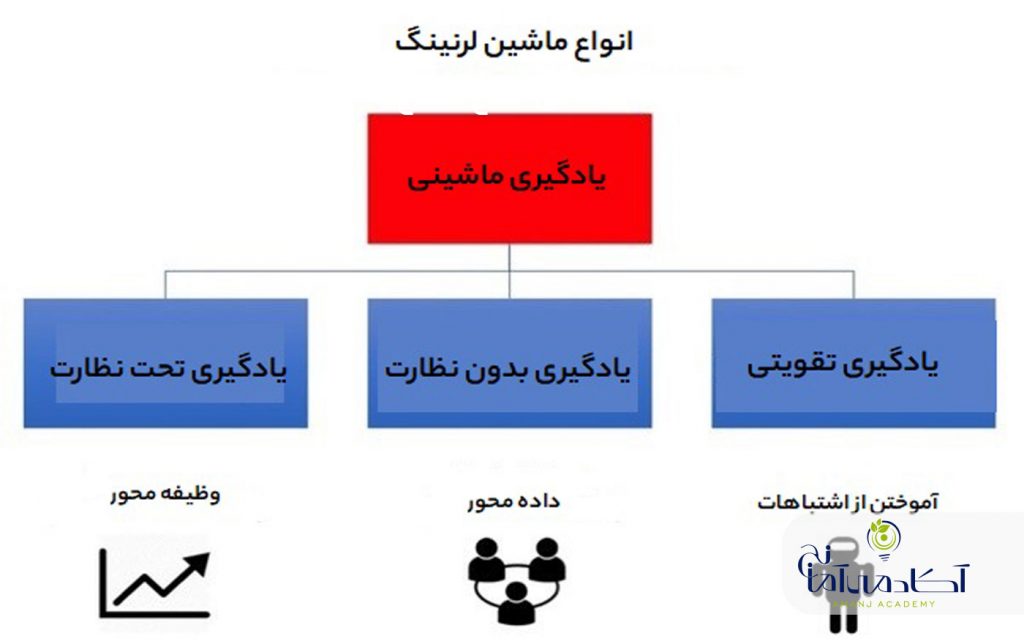
یادگیری ماشین یا ماشین لرنینگ به طور عمده به سه دسته شناخته شده تقسیم میشود: یادگیری نظارت شده ، یادگیری بدون نظارت و یادگیری تقویتی.
در دنیای اشباع شده از هوش مصنوعی ، یادگیری ماشین و تحقیقات غیرقابل توصیف درباره هر دوی این ها ، بد نیست انواع یادگیری ماشینی را که ممکن است با آن روبرو شویم را به طور کامل بشناسیم و درک کنیم . برای اکثر کاربران رایانه ، این موضوع می تواند به درک انواع یادگیری ماشین و نحوه استفاده از آنها در برنامه هایی که استفاده می کنند ، کمک کند . و برای متخصصانی که این برنامه ها را ایجاد می کنند ، ضروری است که انواع یادگیری ماشین را بدانند تا برای هر پروژه خاصی که ممکن است با آن روبرو شوند، بتوانند از روش یادگیری ماشینی مناسب استفاده کرده و نحوه ی کار آن را درک کنند. پس با ما همراه باشید تا نگاه دقیق تری بر این موضوع داشته باشیم :
آنچه در این نوشته خواهیم داشت
یادگیری تحت نظارت
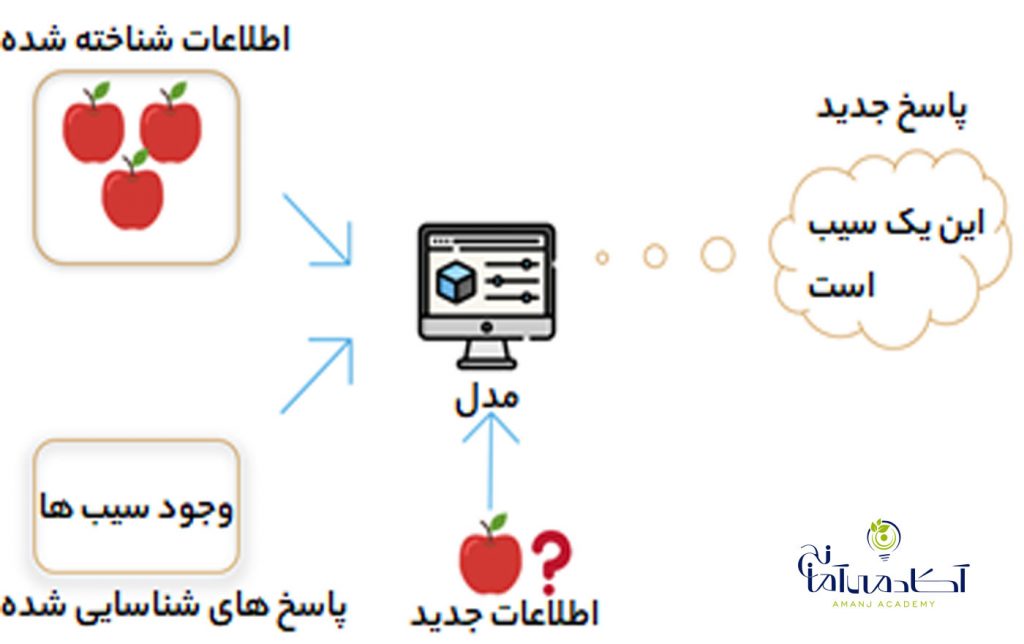
یادگیری نظارت شده محبوب ترین روش برای یادگیری ماشین است. به دلیل ساده ترین درک و ساده ترین اجرا… این نوع یادگیری بسیار شبیه آموزش کودک با استفاده از فلش کارت است.

با توجه به داده های وارد شده و در قالب مثال هایی با برچسب ها ، می توانیم یک الگوریتم یادگیری را ایجاد کنیم. به الگوریتم اجازه می دهیم که برای هر مثال برچسب را پیش بینی کند و به آن بازخورد بدهد که آیا پاسخ درست را پیش بینی کرده است یا نه. با گذشت زمان ، الگوریتم یاد می گیرد که ماهیت دقیق رابطه بین نمونه ها و برچسب های آنها را تقریبی کند. هنگامی که به طور کامل آموزش داده شود ، الگوریتم یادگیری نظارت شده قادر به مشاهده یک نمونه جدید که هرگز قبلا با آن مواجه نشده میشود و برچسب خوبی را برای آن پیش بینی می کند.
یادگیری نظارت شده اغلب با عنوان وظیفه محور توصیف می شود و بسیار متمرکز بر یک کار منفرد است ، در طی روند یادگیری تحت نظارت نمونه های بیشتر و بیشتری را به الگوریتم میدهیم تا زمانی که بتواند به طور دقیق کار مد نظر ما را انجام دهد.
موارد استفاده از یادگیری تحت نظارت :
محبوبیت تبلیغات:
انتخاب آگهی هایی که عملکرد خوبی داشته باشند ، اغلب کار یادگیری تحت نظارت است. بسیاری از تبلیغاتی که هنگام مرور اینترنت مشاهده می کنید توسط ماشین لرنینگ قرار می گیرند زیرا یک الگوریتم یادگیری گفته است که کدام یک از آگهی ها محبوبیت معقول و منطقی دارند ( قابلیت کلیک کردن).
علاوه بر این ، قرار دادن آن در یک سایت خاص (اگر نتایج خود را با استفاده از موتور جستجو می یابید) عمدتاً ناشی از یک الگوریتم آموزش داده شده است. ( تطبیق بین نوع آگهی و نمایش آن)
طبقه بندی هرزنامه:
اگر از سیستم نامه الکترونیکی مدرن استفاده می کنید (ایمیل) احتمال دارد که با فیلتر اسپم روبرو شوید. این فیلتر اسپم یک سیستم یادگیری نظارت شده است. این سیستم ها یاد می گیرند که چگونه ایمیل های مخرب را به صورت پیشگیرانه فیلتر کنند تا کاربر مورد آزار و اذیت آنها نباشد. بسیاری از این موارد نیز به گونه ای رفتار می کنند که کاربر می تواند برچسب های جدیدی را به سیستم ارائه دهد تا این سیستم ها بتوانند ترجیح کاربر را تشخیص داده و بیاموزند.
تشخیص چهره:
آیا از Facebook استفاده می کنید؟ به احتمال زیاد چهره شما به عنوان داده در یک الگوریتم یادگیری نظارت شده استفاده شده است و سیستم استفاده شده در فیسبوک برای تشخیص چهره شما آموزش دیده است.این سیستم ، چهره ها را پیدا می کند ، و حدس می زند چه کسی در عکس است و کاربران را شناسایی میکند (نشان برچسب را نشان می دهد) این عمل یک فرایند تحت نظارت است.
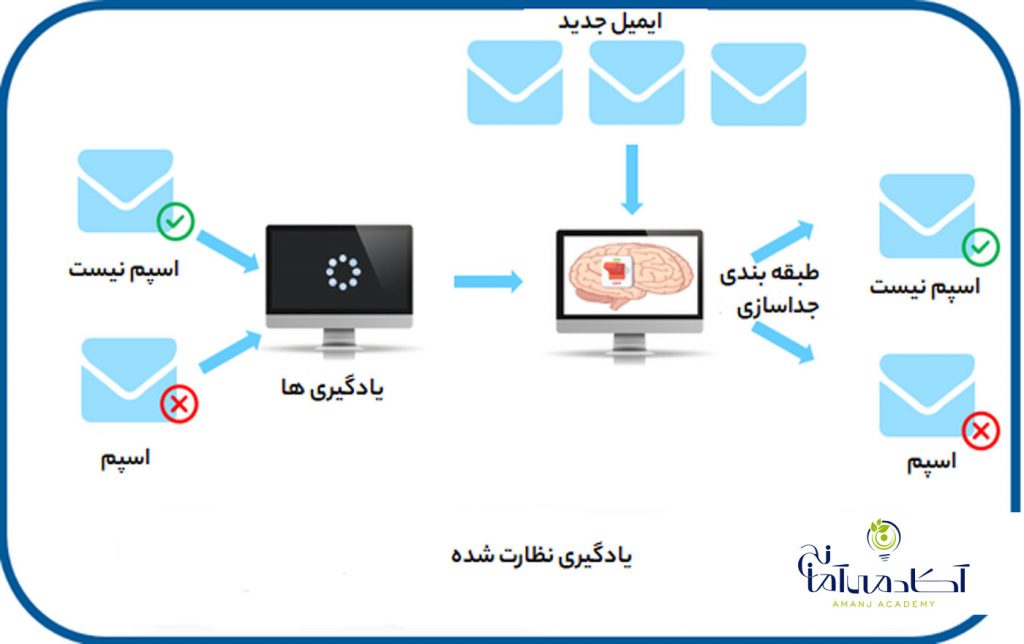
یادگیری بدون نظارت
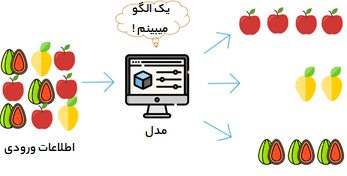
یادگیری بدون نظارت کاملاً بر خلاف یادگیری نظارت شده است. این نوع یادگیری فاقد برچسب است. در عوض ، به الگوریتم ما داده های زیادی داده می شود و همینطور به آن ابزاری برای درک ویژگی های داده داده می شود.
در این حالت، مدل از طریق مشاهدات یادگیری کرده و دستورالعملها و ساختارهای موجود در مجموعهی دادهها را کشف میکند. زمانی که مجموعه دادهای به مدل معرفی میشود. مدل با استفاده از گروه بندی ، خوشه بندی و یا سازماندهی داده ها، ارتباطات و الگوهای موجود در آنها را بهصورت اتوماتیک کشف میکند.
چیزی که باعث می شود یادگیری بدون نظارت جالب توجه شود این است که اکثریت قریب به اتفاق داده ها در این جهان فاقد مارک و برچسب هستند. داشتن الگوریتم های هوشمندی که می تواند ترابایتها داده ی بدون مارک ما را به خود اختصاص داده و از آن ها معنا و ارتباط پیدا کند منبع بزرگی از سود بالقوه برای بسیاری از صنایع است و به تنهایی می تواند به افزایش بهره وری در چندین زمینه کمک کند.
به عنوان مثال ، اگر یک بانک اطلاعاتی بزرگ از هر مقاله تحقیقاتی که تاکنون منتشر شده است ، داشته باشیم و الگوریتمهای یادگیری بدون نظارتی داشته باشیم که می دانستند چگونه اینها را به گونه ای دسته بندی کنند ، به طوری که شما همیشه از پیشرفت فعلی در یک دامنه خاص تحقیق، مطلع باشید. اکنون ، شما خودتان شروع به ایجاد یک پروژه تحقیقاتی می کنید و کار خود را به این شبکه وصل می کنید که الگوریتم می تواند آن را ببیند. وقتی کار خود را می نویسید و یادداشت می کنید ، الگوریتم درمورد کارهای مرتبط ، آثاری که ممکن است بخواهید از آنها استناد کنید ، و آثاری که حتی ممکن است در پیشبرد دامنه تحقیقتان به شما کمک کند ، به شما پیشنهاداتی می دهد. بدون شک با چنین ابزاری می توان بهره وری شما را بسیار بالا برد.
از آنجا که یادگیری بدون نظارت مبتنی بر داده ها و خصوصیات آن است ، می توان گفت که یادگیری بدون نظارت داده محور است. نتایج حاصل از یک کار یادگیری بدون نظارت توسط داده ها و نحوه شکل گیری آن کنترل می شود.
نمونه هایی از کارایی یادگیری بدون نظارت :
سیستم های پیشنهادی:
اگر تاکنون از YouTube یا Netflix استفاده کرده اید ، به احتمال زیاد با یک سیستم توصیه ویدیویی روبرو شده اید. این سیستم ها غالباً در دامنه بدون نظارت قرار می گیرند.سیستم با توجه به فیلم ها ، طول آنها ، ژانر آنها، تاریخچه تماشای بسیاری از کاربران، کاربرانی که فیلم های مشابه شما را تماشا کرده اند و یا فیلم های دیگری که هنوز مشاهده نکرده اید و به کمک تحلیل این داده ها،به شما پبشنهادات جدیدی میدهد.
عادات خرید مشتریان :
این احتمال وجود دارد که عادات خرید شما در جایی از پایگاه داده موجود باشد. این عادات خرید را می توان در الگوریتم های یادگیری بدون نظارت برای گروه بندی مشتریان در بخش های خرید مشابه استفاده کرد. این روش به شرکتها کمک می کند تا در این بخش های گروه بندی بازاریابی کنند و حتی می توانند شبیه سیستم های پیشنهادی باشند.
گروه بندی سوابق کاربران:
می توانیم از یادگیری بدون نظارت برای گروه بندی سوابق و مشکلات کاربران استفاده کنیم. این امر می تواند به شرکتها کمک کند تا موضوعات اصلی را برای حل مشکلات مشتری خود تشخیص دهند و این مشکلات را از طریق بهبود یک محصول یا طراحی سؤالات متداول برای رسیدگی به مسائل مشترک ، اصلاح کنند. در هر صورت ، این کاری است که به صورت اتوماتیک انجام می شود و اگر تاکنون مشکلی با یک محصول داشته اید و گزارش اشکال را به شرکتی ارسال کرده اید ، احتمالاً آن را به یک الگوریتم یادگیری بدون نظارت داده اید تا آن را با سایر موضوعات مشابه دسته بندی کند!
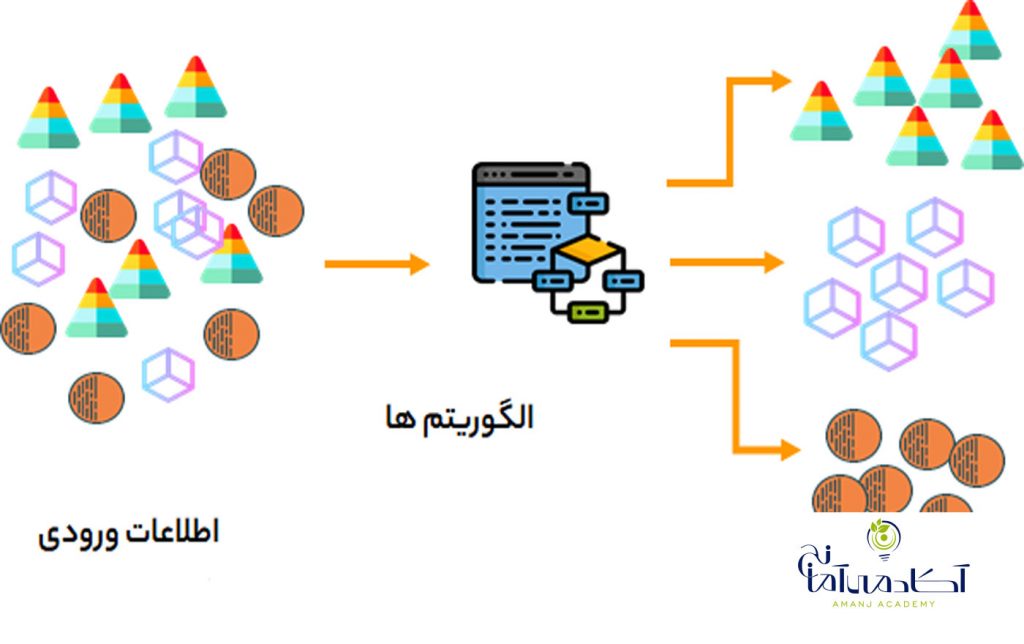
یادگیری تقویتی
یادگیری تقویتی در مقایسه با یادگیری نظارت شده و تحت نظارت نسبتاً متفاوت است. دواقع توسط یادگیری تقویتی به راحتی می توانیم رابطه بین یادگیری نظارت شده و نظارت نشده (وجود یا عدم وجود برچسب ها) را ببینیم .درک یادگیری تقویت کننده کمی مشکل است. بعضی از افراد سعی می کنند با توصیف آن به عنوان نوعی یادگیری که به دنباله های وابسته به زمان مرتبط است ، یادگیری تقویت کننده را آسان ترکنند، با این حال ، نظر من این است که این نوع یادگیری به سادگی باعث سردرگمی می شود.
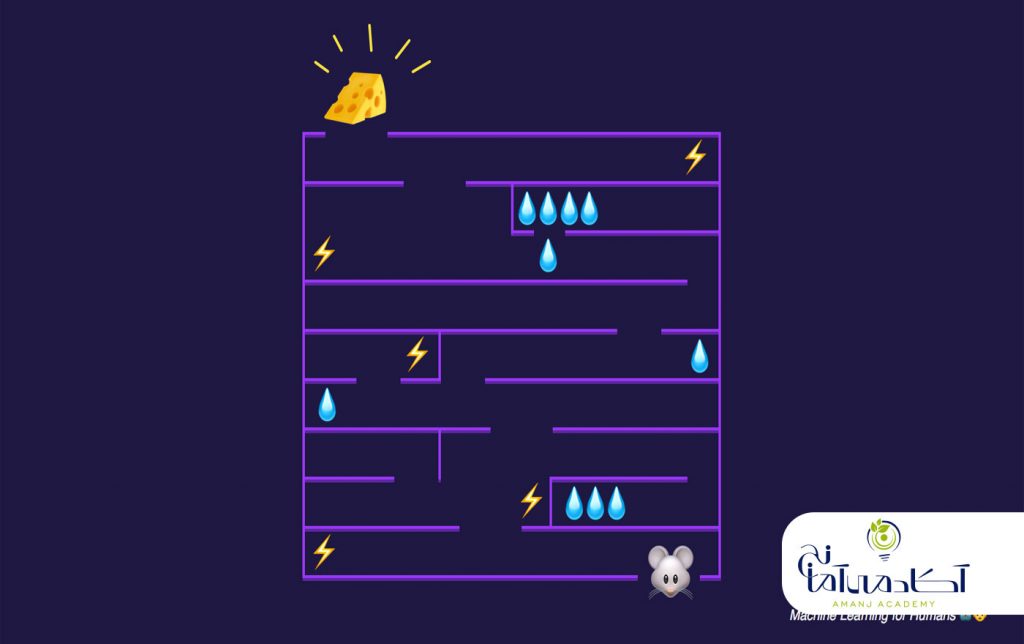
من ترجیح می دهم یادگیری تقویتی را به عنوان یادگیری از اشتباهات بیان کنم. یک الگوریتم یادگیری تقویت کننده در ابتدا اشتباهات زیادی را به دنبال خواهد داشت. تا زمانی که ما نوعی سیگنال را به الگوریتم ارائه دهیم که رفتارهای خوب را با یک سیگنال مثبت و رفتارهای بدرا با یک سیگنال منفی همراه کند. به این ترتیب می توانیم الگوریتم خود را تقویت کنیم تا رفتارهای خوب را نسبت به رفتارهای بد ترجیح دهد. با گذشت زمان ، الگوریتم یادگیری ما می آموزد و کمتر از قبل اشتباه می کند.
یادگیری تقویتی بسیار رفتارمحور است.اگر نظره سگ پاولوف را شنیده اید ، ممکن است از قبل با ایده تقویت یک عامل ، هر چند بیولوژیکی ، آشنا باشید.
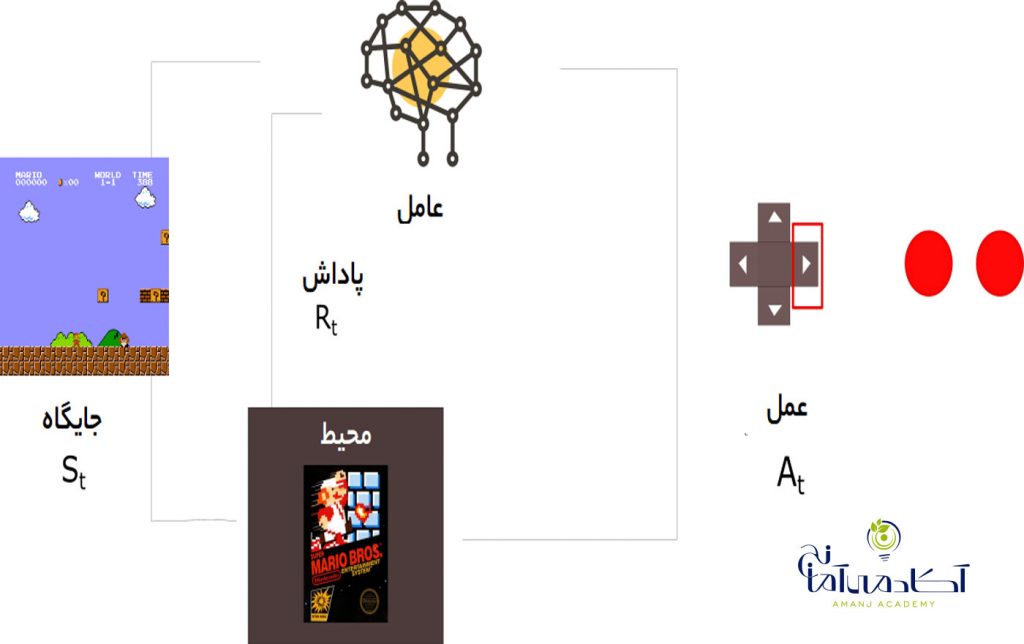
با این حال ، برای درک واقعی یادگیری تقویت ، یک مثال مشخص را بیان می کنیم. بیایید به آموزش یک عامل برای بازی Mario بپردازیم:
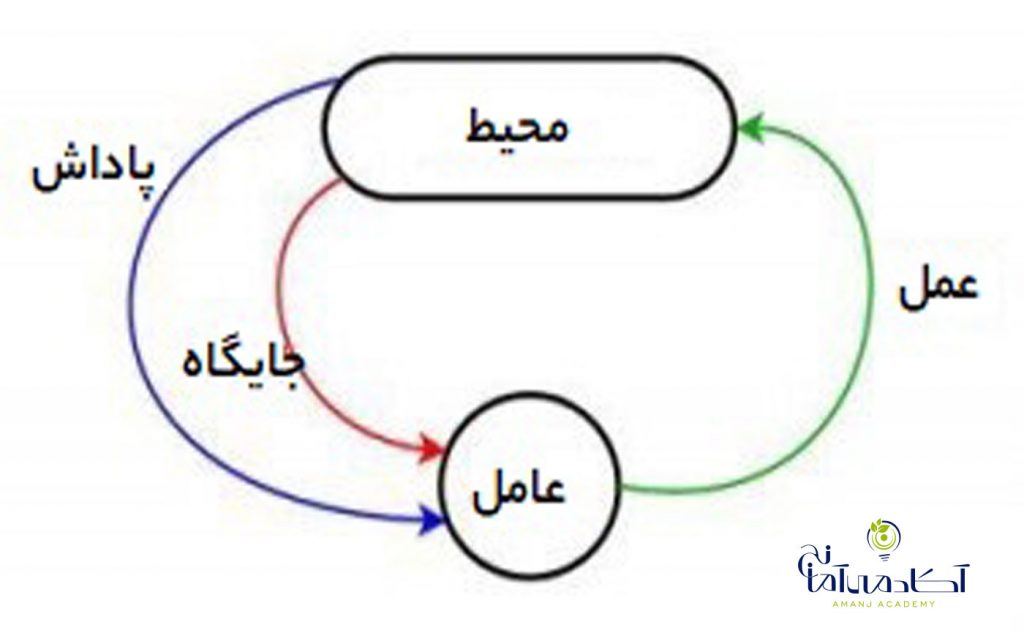
برای هرگونه یادگیری تقویتی ، به یک عامل و یک محیط و همچنین راهی برای اتصال این دو از طریق یک حلقه بازخورد نیاز داریم. برای اتصال عامل به محیط ، ما به آن مجموعه اقداماتی می دهیم که می تواند انجام دهد و این امر بر محیط تأثیر می گذارد. برای اتصال محیط به عامل ، ما به طور مداوم دو سیگنال را به عامل صادر می کنیم: یک وضعیت به روز شده و یک پاداش (سیگنال تقویت کننده ما برای رفتار).
در بازی ماریو ، عامل ما الگوریتم یادگیری ما است و محیط ما بازی (به احتمال زیاد یک سطح خاص) است. نماینده ما مجموعه ای از اقدامات را پیش رو دارد. (حالت های دکمه ما ). با گذشت زمان ، وضعیت به روز شده ما درواقع هر فریم بازی خواهد بود و سیگنال پاداش ما ،تغییر در امتیاز خواهد بود. اگر همه این مؤلفه ها را به هم متصل کنیم ، یک سناریوی یادگیری تقویتی برای بازی Mario تنظیم خواهیم کرد.
کاربرد یادگیری تقویتی در دنیای واقعی :
بازی های ویدئویی:
یکی از رایج ترین مکان ها برای یادگیری تقویتی ، یادگیری بازی کردن است. همانند برنامه یادگیری تقویتی Google ، AlphaZero و AlphaGo
در حال حاضر، هیچ نوع بازی که یک عامل یادگیری تقویت کننده دارد و بر هوش مصنوعی متکی باشد را نمیشناسم ، اما می توانم تصور کنم که این بزودی ایده جالبی خواهد بود.
شبیه سازی صنعتی:
برای بسیاری از برنامه های کاربردی روباتیک (خطوط مونتاژ ) استفاده میشود . بهتر است که ماشینهای ما یاد بگیرند کارهای خود را بدون نیاز به رمزگشایی در روند کار خود انجام دهند. این می تواند یک گزینه ارزان تر و مطمئن تر باشد. حتی می تواند کمتر مستعد شکست باشد. ما همچنین می توانیم دستگاه های خود را برای استفاده از برق کم تر تشویق کنیم تا در هزینه خود صرفه جویی کنیم و به کمک این شبیه سازی مانع خراب شدن دستگاه نیز می شویم.
مدیریت منابع:
یادگیری تقویتی برای پیمایش در محیطهای پیچیده مناسب است. این نوع یادگیری می تواند نیاز به تعادل در برخی از شرایط را برطرف کند. به عنوان مثال ، مراکز داده Google : آنها از یادگیری تقویتی برای برآورده کردن نیازهای انرژی و حفظ تعادل استفاده می کنند و هزینه های اصلی را کاهش می دهند. این مسئله چه تاثیری در کار ما و افراد معمولی دارد؟ ارزان تر کردن ذخیره سازی داده ها برای ما و همچنین تأثیر کمتر بر محیطی که همه ما در آن قرار گرفته ایم
ادغام انواع یادگیری ماشین
اکنون که ما در مورد سه دسته مختلف یادگیری ماشین صحبت کرده ایم ، لازم به ذکر است که مرز بین این سه نوع یادگیری مبهم است. کارهای زیادی وجود دارد که به راحتی می توان آنها را به عنوان یک نوع یادگیری بیان کرد وحتی به یک الگوی دیگر تبدیل کرد.
به عنوان مثال ، یک سیستم پیشنهادی را انتخاب کنید. ما آن را به عنوان یک کار یادگیری بدون نظارت مورد بحث قرار دادیم. این سیستم همچنین به راحتی می تواند به عنوان یک کار تحت نظارت تغییر داده شود. مثلا با توجه به سابقه تماشای کاربران ، پیش بینی کنید که فیلم خاصی باید توصیه شود یا نه.
همچنین ایده جالب تر این است که ما می توانیم این نوع یادگیری ها را بسازیم ، و مؤلفه هایی از سیستم ها را طراحی کنیم که به یک روش یادگیری یاد می گیرند ، اما در یک الگوریتم بزرگتر با هم ادغام می شوند
برای مثال نماینده ای که ماریو را بازی می کند. چرا توانایی یادگیری نظارت شده را در شناخت و برچسب زدن دشمنان به آن نمی دهیم؟
و یا سیستمی که جملات را طبقه بندی می کند. چرا این توانایی را به وجود نمی آوریم که بتوانیم از بازنمایی معنای جمله ، که از طریق یک فرآیند بدون نظارت آموخته می شود ، سرمایه گذاری کنیم؟
آیا می خواهید افراد را در یک شبکه اجتماعی به بخش های کلیدی و گروه های اجتماعی تقسیم بندی کنید؟ چرا یک فرآیند تقویتی که نوع نمایندگی افراد را بسنجد اضافه نکنیم تا بتوانیم با دقت بیشتری افراد را جمع کنیم؟
بسیار مهم است که همه ما تا حدودی اصول یادگیری ماشین را درک کنیم ، حتی اگر هرگز خودمان یک سیستم یادگیری ماشین ایجاد نکنیم.زیرا در دنیای امروز ما ماشین لرنینگ به طور فزاینده ای استفاده شده و رواج دارد. همینطور درک اصول یادگیری ماشینی به ما کمک می کند تا بتوانیم در مورد فن آوری های مورد استفاده خود بهتر استدلال کنیم…
- ۰ ۰
- ۰ نظر