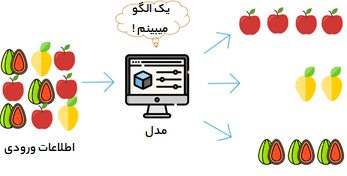
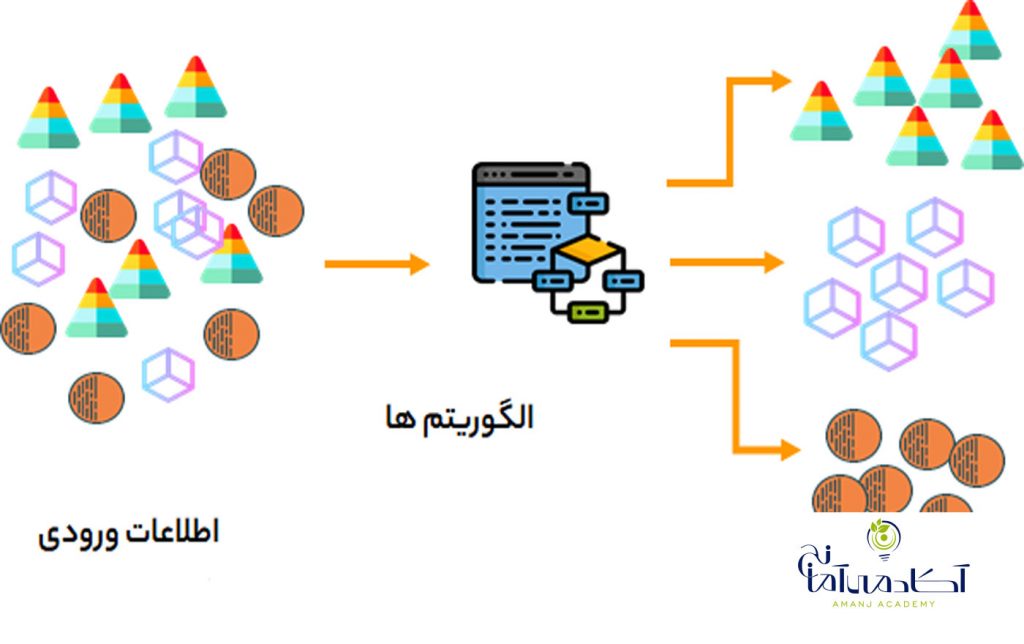
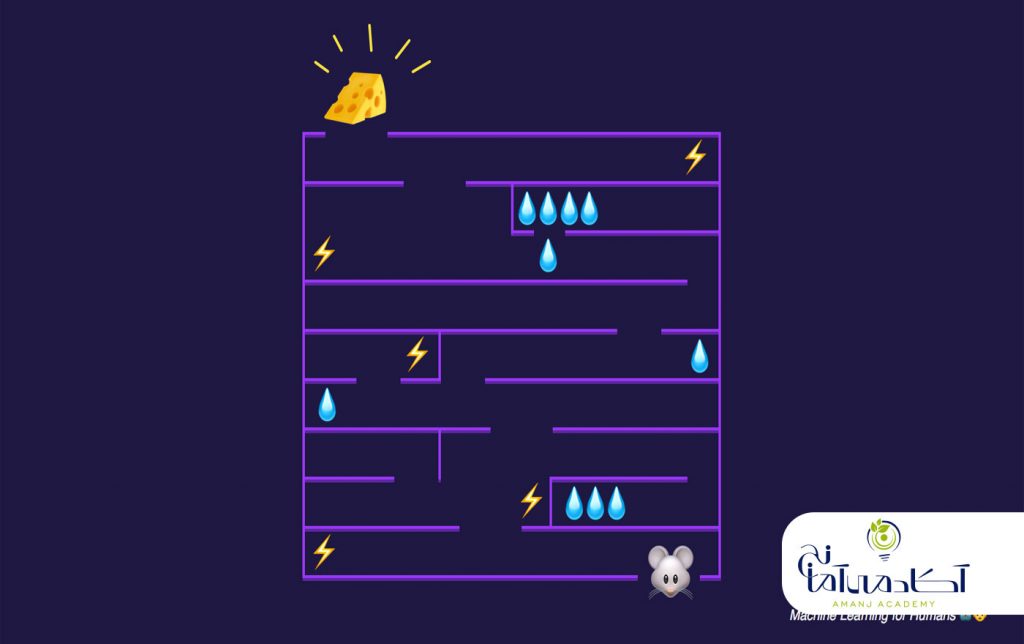
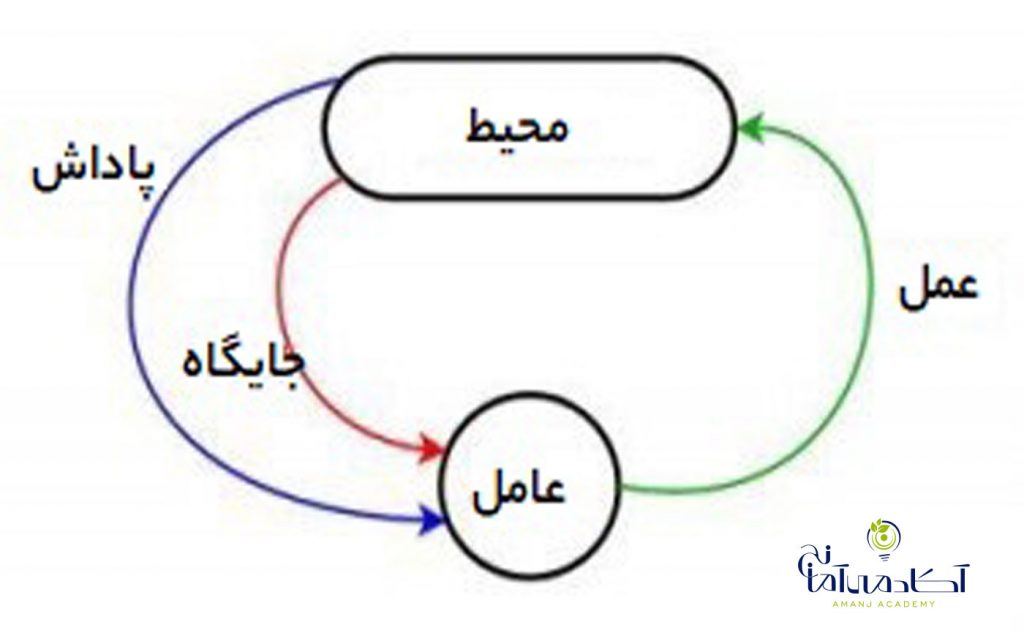
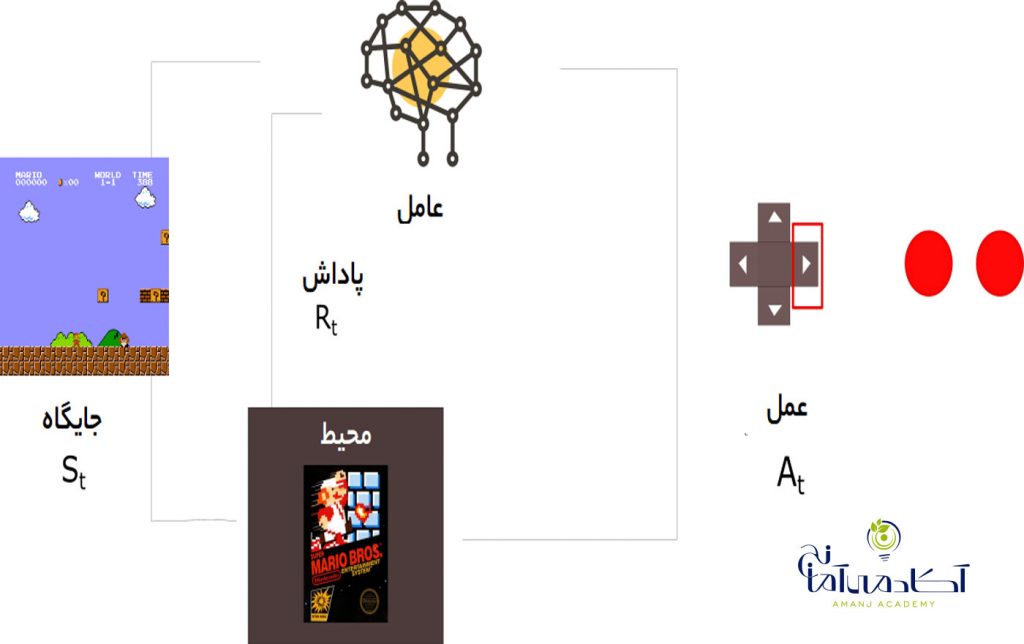
پایتون به عنوان زبان ارجح برای آموزش و یادگیری Ml (یادگیری ماشین) مورد استفاده قرار می گیرد . همچنین به عنوان یک زبان برنامه افزودنی برای برنامه هایی که به زبان های دیگر نوشته شده اند و نیاز به رابط های اسکریپت یا اتوماسیون آسان دارند ، قابل استفاده است. یادگیری ماشین با پایتون یک نقطه شروع خوب برای Ml است و شما می توانید از آن برای استفاده از مدلهای موجود مانند رگرسیون خطی ، رگرسیون لجستیک و SVM استفاده کنید.ولی اگر در مورد یادگیری ماشین جدی تر هستید بهتر است برخی از کتابهای ریاضیات را نیز درک کنید. در این مقاله با 8 کارایی شگفت انگیز ماشین لرنینگ با پایتون آشنا خواهیم شد .

1. سادگی خواندن و نوشتن در پایتون
تنها دلیل انتخاب پایتون به عنوان زبان مقدماتی برای برنامه نویسی ، سادگی آن است. پایتون ساده اما قدرتمند است. نوشتن پایتون آسان است ودرک آسانی دارد. شرایطی مانند گرفتن کد شما از یک توسعه دهنده دیگر که از مؤلفه های شخص ثالث استفاده می کند به این معنی است که شما نیاز به سرورهای شناختی بسیار کمی دارید. همچنین خوانایی کدها بیشترازچیزی است که نوشته شده است. بنابراین ، سادگی خدمت بزرگی برای پایتون محسوب می شود.
2. مجموعه عظیمی از کتابخانه های مرتبط در پایتون
پایتون برای اهداف یادگیری ماشینی مجموعه گسترده ای از کتابخانه ها را در اختیار دارد. اینها شامل Python NumPy ، SciPy ، scikit-Learn و موارد دیگر است. که برای تمام کارهای ذاتی یادگیری ماشین کاربرد دارند..
scikit-Learn– برای داده کاوی ، تجزیه و تحلیل داده ها و یادگیری ماشین مناسب است.
pylearn– انعطاف پذیر تر از scikit-Learn میباشد.
کتابخانه ماژولار PyBrain با الگوریتم های یادگیری ماشین انعطاف پذیر ، آسان و قدرتمند و محیط های از پیش تعریف شده برای آزمایش و مقایسه الگوریتم ها مناسب است.
orange – کمک به تجسم و تجزیه و تحلیل داده ها با منبع باز ، دارای مؤلفه هایی برای یادگیری ماشین ، دارای پسوندهایی برای سنجش بیومتریک و استخراج متن، پشتیبانی از داده کاوی از طریق برنامه نویسی بصری یا برنامه نویسی پایتون است.
PyML– چارچوب تعاملی شی گرا برای یادگیری ماشین ، که در پایتون نوشته شده است.
Milk_ دارای SVM ، k-NN ، جنگلهای تصادفی ، درختان تصمیم گیری ، که انتخاب ویژگی را انجام می دهد.
Shogun– ابزار یادگیری ماشین ، متمرکز بر روش های کرنل بزرگ مقیاس و SVM ها میباشد.
Tensorflow_کتابخانه شبکه عصبی سطح بالا میباشد.
برنامه های کاربردی آموزش ماشین با پایتون
1. پیش بینی گزینه های موسیقی
محصولاتی مانند Genius توسط Apple Music بر آنچه شما گوش می دهید نظارت می کند. بعداً ، می تواند لیستی از آهنگهایی را که احتمالاً ترجیح می دهید به شما پیشنهاد دهد. همچنین آهنگهایی را از لیست پخش شما انتخاب می کند تا کتابخانه هایی مشابه با یکدیگرایجاد شود.
2. کشف مواد مخدر و تشخیص بیماری با الگوریتم های ماشین لرنینگ می توانیم کارهای زیر را به کمک یادگیری ماشین دراین زمینه انجام دهیم :
می توانیم کارهای زیر را به کمک یادگیری ماشین دراین زمینه انجام دهیم :
- برنامه های کاربردی آموزش ماشین با پایتون
- غربالگری اولیه ترکیبات دارویی
- پیش بینی میزان موفقیت بر اساس عوامل بیولوژیکی
- فن آوری های تحقیق و توسعه مانند نسل بعدی توالی
- فرآیندهای بیماری را درک کنید.
- درمان هایی مؤثر برای بیماری ها طراحی کنید.
- شخصی سازی ترکیبات دارویی.
- داروهای ارزان تر با همانندسازی بهبود یافته تولید کنید.
- تحقیق و توسعه روش های تشخیصی و درمانی.
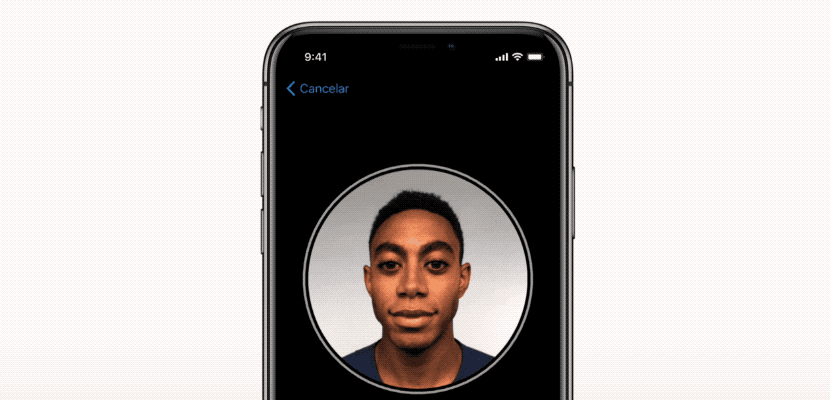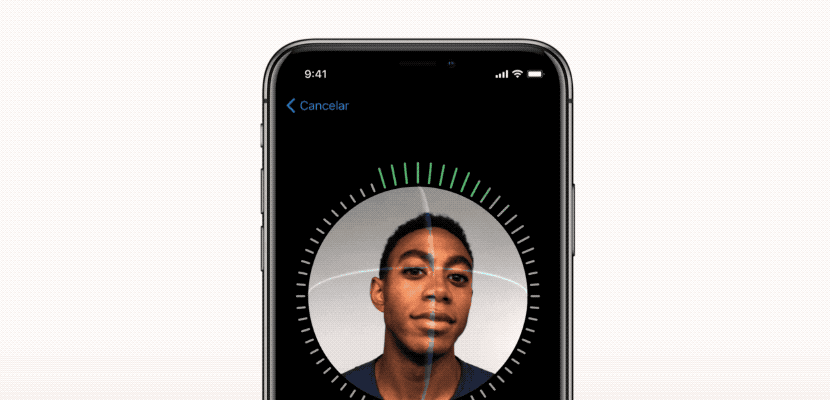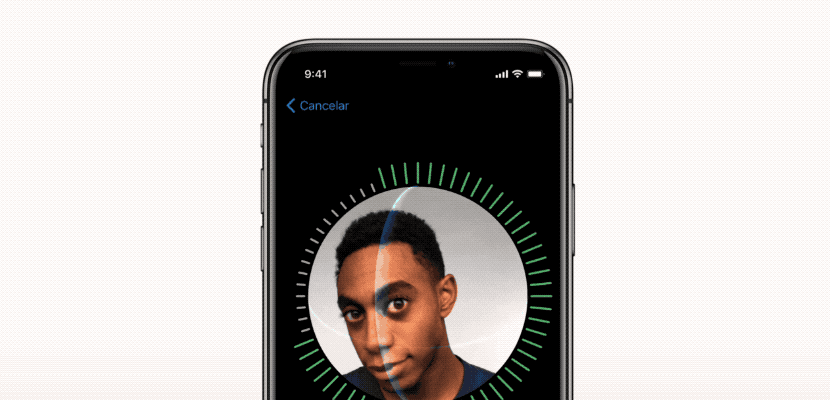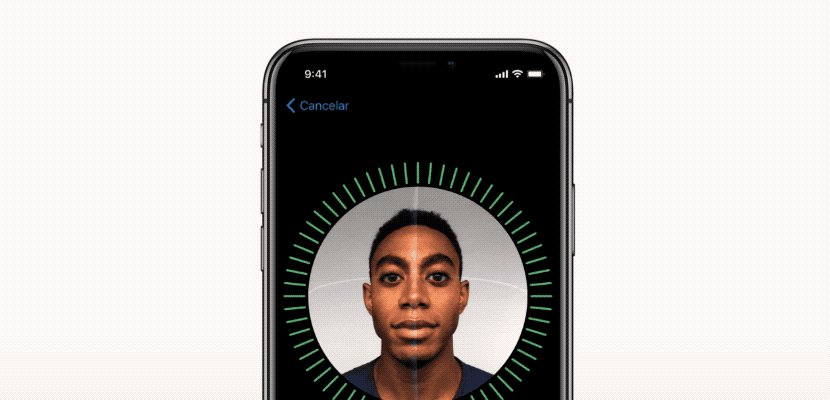
3. تشخیص چهره

امکاناتی مانند تشخیص چهره به کمک ماشین لرنینگ اغلب مواردی است که با Facebook می بینیم. وقتی می خواهیم یک عکس را برچسب گذاری کنیم ، فیس بوک به طور خودکار چند نام را به ما پیشنهاد می دهد و در اکثر اوقات ، نام او برای چهره ای که کشف کرده است به کمک یادگیری ماشینی دقیق است.
4. دستیاران شخصی مجازی

نام هایی مانند سیری و الکسا قابلیت دستیاران مجازی را به خاطر می آورند. ما می توانیم از سیری بخواهیم برایمان تماس بگیرد یا موسیقی بخواند. برای پیش بینی وضع هوا امروز می توانید از الکسا سوال کنید. حتی می توانید زنگ خطر را تنظیم کرده یا پیامک ارسال کنید. فقط باید با آن صحبت کنید و به فرمان شما گوش فرا می دهد.این دستیارها به نحوه تعامل شما با آنها توجه می کنند و از آن استفاده می کنند تا تجربه بعدی شما را بهتر کنند.
5. خدمات رسانه های اجتماعی

این برنامه از یادگیری ماشینی برای نظارت بر فعالیت شما استفاده می کند. چه پروفایل هایی را که بازدید می کنید ، چه افرادی را برای آن ها درخواست دوستی میفرستید یا افرادی که درخواست های آنها را می پذیرید وهمینطور افرادی که برچسب گذاری می کنید …
فیس بوک امیدوار است تجربه غنی تری را در پلتفرم خود به شما ارائه دهد ، بنابراین شما مرتباً از یادگیری ماشین با پایتون در آن استفاده خواهید کرد.
6. اتومبیل های خودران

این اتومبیل داده ها راجع به اشیاء اطراف و اندازه و سرعت آنها از طریق سنسورها دریافت می کنند و براساس نحوه رفتار آنها ، اشیاء را به عنوان دوچرخه سوار ، پیاده و سایر اتومبیل ها طبقه بندی می کند.سپس از این داده ها برای مقایسه نقشه های ذخیره شده با شرایط فعلی استفاده می کند. چنین اتومبیل هایی از الگوریتم های Machine Vision استفاده می کنند.
7. پشتیبانی آنلاین مشتری
وب سایتهای آموزشی و سیستم عاملهای خرید اغلب یک گپ زنده را برای کمک به سوالات خود ایجاد می کنند. بازدید کننده ای با کلی سؤال بی جواب ،احتمالاً خرید خود را ترک می کند.ولی برخی از وب سایتها از یک ********bot برای جلب اطلاعات به وب سایت استفاده می کنند و سعی می کنند به سؤالات مشتری بپردازند.
8. نظارت تصویری

قبل از وقوع برخی از جرائم می توان با نظارت و شناسایی رفتار افراد از آنها جلوگیری کرد.ماشین لرنینگ با پایتون رفتارهایی مانند ایستادن بی حرکت ، چرت زدن روی نیمکت و پیروی از فرد دیگر را می تواند از طریق سیستم نظارت تصویری به انسان هشدار دهد.
9. توصیه های محصول
سیستم عاملهای خرید مانند آمازون و جابونگ متوجه می شوند چه کالاهایی را مشاهده می کنید و محصولات مشابه را برای شما پیشنهاد می کنند. اگر این محصول مورد علاقه شما به دست شما برسد و به خریدی که انجام داده اید منجر شود ، این یک برد برای آنها است. برای تشخیص محصولات به کمک ماشین لرنینگ از لیست دلخواه، سبد خرید و مشاهدات شما استفاده می کنند.
10. برنامه های قیمت گذاری بیمه

یادگیری ماشینی می تواند تشخیص دهد که آیا راننده احتمالاً در طول مدت بیمه باعث ایجاد یک خسارت بزرگ شده است یا نه . این به شرکت های بیمه اجازه می دهد تا برنامه های بیمه قیمت را بر این اساس تنظیم کنند.
11. ترجمه خودکار

ماشین لرنینگ با پایتون به ما امکان می دهد یک متن را به زبانی دیگر ترجمه کنیم. الگوریتم ماشین لرنینگ برای این کار از شکل چگونگی قرارگیری کلمات در کنار هم استفاده میکند و سپس از این اطلاعات برای بهبود کیفیت ترجمه استفاده می کنند. با این کار، ما همچنین می توانیم متون روی تصاویر را با استفاده از شبکه های عصبی و شناسایی حروف ترجمه کنیم.
12. تشخیص کلاهبرداری های آنلاین

اگر با PayPal آشنا هستید ، PayPal از یادگیری ماشینی برای دفاع در برابر اقدامات غیرقانونی مانند پولشویی استفاده می کند. با مقایسه میلیون ها تراکنش می توان فهمید که کدام یک از آنها نامشروع است.
کارایی های بیشتر یادگیری ماشین با پایتون
به غیر از مواردی که ذکر کردیم ، می توانیم از Machine Learning برای اهداف زیر استفاده کنیم :
- شناسایی ژنهای انسانی که مستعد ابتلا به سرطان هستند.
- شناسایی محصولاتی که مصرف کنندگان به آن واکنش نشان می دهند.
- معاملات سهام و مشتقات.
- بازرسی بسته برای نرم افزار ضد ویروس.
- تشخیص تاخیر در پروازهای هواپیما.
- تشخیص تعمیرات و نگهداری کارخانه.
- تبلیغات رفتاری برای محصولات.
موارد ذکر شده همگی در مورد برنامه های کاربردی یادگیری ماشین با پایتون میباشد. امیدوارم توضیحات ما در این خصوص برایتان مفید بوده باشد.
اگر میخواهید فایل پی دی اف این مقاله را دریافت کنید یا آن را برای دیگران ارسال کنید در لینک زیر در دسترس میباشد .
- ۰ ۰
- ۱ نظر